Hello all,
doing few NetApp vs TSM NDMP tests.
TSM v 5.3.6.0 (will be upgraded, but do not think it is relevant now)
NetApp FAS3040 (IBM n5300)
IBM LTO4 drives in TS3310 - connected via FC to filer
What seems strange to me is that when I backup one volume (300GB) it takes roughly 3hrs (without TOC - I do not need one)
Now I am doing restore to alternate volume on the same filer (full+diff)
After almost 2hrs the process is at 2,8GB so the estimation is cca 8 days
Load of the filer is CPU <20%, disk <50% (restore is running)
using NDMP v4
command used for backup
backup node netapp1 /vol/path toc=no mode=full (one day old)
backup node netapp1 /vol/path toc=no mode=diff (current)
command used for restore
restore node netapp1 /vol/path /vol/newpath
Any real-world comparison? Hint?
Thanks
Harry
*************
UPDATE
*************
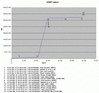
the speed seems to be very far from constant ...
After cca 11hrs I have about 90GB restored and current speed is roughly 15GB/hr (started at 1GB/hr)
Filer's statistics are almost the same:
CPU <35%, disk <55%
Do all have the same experience?
doing few NetApp vs TSM NDMP tests.
TSM v 5.3.6.0 (will be upgraded, but do not think it is relevant now)
NetApp FAS3040 (IBM n5300)
IBM LTO4 drives in TS3310 - connected via FC to filer
What seems strange to me is that when I backup one volume (300GB) it takes roughly 3hrs (without TOC - I do not need one)
Now I am doing restore to alternate volume on the same filer (full+diff)
After almost 2hrs the process is at 2,8GB so the estimation is cca 8 days
Load of the filer is CPU <20%, disk <50% (restore is running)
using NDMP v4
command used for backup
backup node netapp1 /vol/path toc=no mode=full (one day old)
backup node netapp1 /vol/path toc=no mode=diff (current)
command used for restore
restore node netapp1 /vol/path /vol/newpath
Any real-world comparison? Hint?
Thanks
Harry
*************
UPDATE
*************
the speed seems to be very far from constant ...
After cca 11hrs I have about 90GB restored and current speed is roughly 15GB/hr (started at 1GB/hr)
Filer's statistics are almost the same:
CPU <35%, disk <55%
Do all have the same experience?
Last edited:
")